

Plik llms.txt to nowy standard komunikacji pomiędzy stronami internetowymi a systemami sztucznej inteligencji. W praktyce działa podobnie do znanego wszystkim pliku robots.txt, jednak jego zadaniem jest nie tyle sterowanie robotami wyszukiwarek, ile kontrola dostępu modeli językowych – takich jak ChatGPT, Gemini, Claude czy Perplexity AI.
Dzięki niemu właściciele stron mogą sami decydować, czy pozwalają modelom AI na analizę i przetwarzanie ich treści. Wraz z rosnącą rolą generatywnych wyszukiwarek i tzw. wyników AI Overviews, plik ten staje się kluczowym elementem strategii SEO i bezpieczeństwa danych w 2025 roku.
Co to jest plik llms.txt i jak działa?
Plik llms.txt to prosty dokument tekstowy, który umieszcza się w głównym katalogu witryny. Zawiera on instrukcje, które mówią systemom AI, jakie treści mogą być analizowane, a które powinny pozostać niedostępne.
Każda zasada w pliku odnosi się do konkretnego programu (np. GPTBot lub Google-Extended) i jest zapisana w formie prostych komend – Allow (zezwól) lub Disallow (zablokuj).
Właściciel strony może więc w prosty sposób wskazać, które sekcje serwisu są otwarte dla sztucznej inteligencji, a które wymagają ochrony.
Takie rozwiązanie zwiększa przejrzystość i pozwala zachować kontrolę nad sposobem, w jaki dane są przetwarzane. Ponieważ coraz więcej modeli AI pobiera treści z sieci, llms.txt staje się narzędziem nie tylko technicznym, lecz także strategicznym.
Dlaczego powstał llms.txt i kto go stosuje?
Początki i inspiracje
Idea stworzenia pliku llms.txt zrodziła się z rosnącej potrzeby ochrony treści przed automatycznym wykorzystywaniem przez sztuczną inteligencję. Twórcy tego standardu wzorowali się na pliku robots.txt, który od lat służy wyszukiwarkom do ustalania zasad indeksowania stron.
Jednak nowa rzeczywistość wymagała nowych rozwiązań – llms.txt został zaprojektowany specjalnie dla modeli językowych, które nie tylko czytają, ale też uczą się na podstawie dostępnych danych.
Kto wspiera ten standard?
Nad rozwojem i promocją pliku llms.txt pracują m.in. firmy OpenAI, Google, Anthropic oraz liczne organizacje zajmujące się etyką i prawem w AI. Celem jest stworzenie globalnego protokołu, który umożliwi jasną komunikację między twórcami treści a systemami sztucznej inteligencji.
Wiele znanych serwisów – od mediów po uczelnie – już wdrożyło ten plik, traktując go jako element własnej polityki przejrzystości i ochrony danych.
Jakie systemy respektują plik llms.txt?
Obecnie plik llms.txt jest respektowany przez największe modele językowe: GPTBot (OpenAI), Google-Extended, ClaudeBot (Anthropic) oraz Perplexity AI.
Każdy z tych botów przed analizą treści sprawdza zasady zapisane w pliku i postępuje zgodnie z nimi. Dla właścicieli stron to ogromna zmiana – mogą oni po raz pierwszy decydować, które dane są wykorzystywane przez modele AI, a które pozostają prywatne.
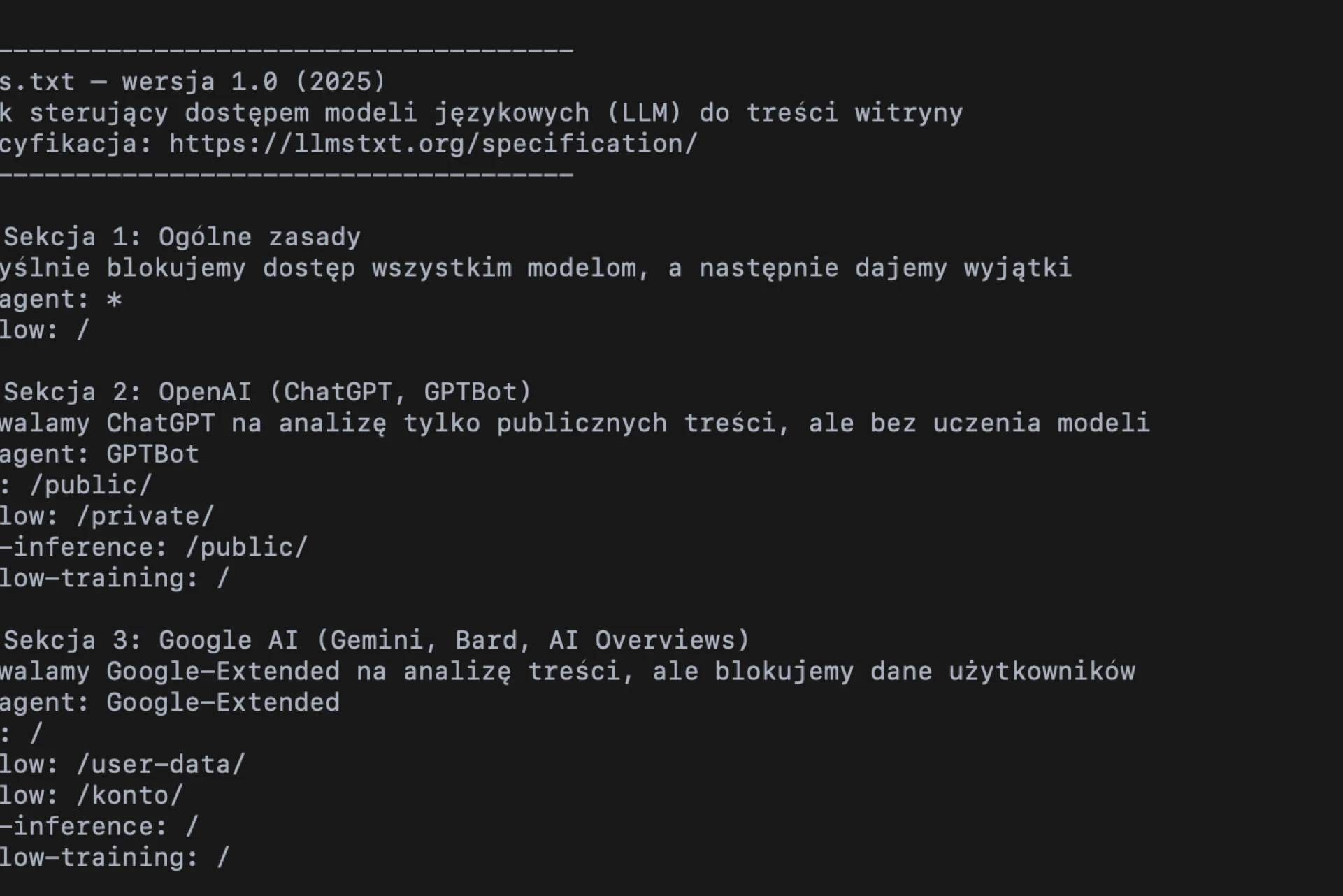
Jak wygląda przykładowy plik llms.txt?
Struktura llms.txt jest prosta i przejrzysta. Wystarczy kilka linijek, aby określić zasady dostępu:
User-agent: GPTBot
Allow: /
User-agent: Google-Extended
Disallow: /private/
Taki zapis oznacza, że ChatGPT może analizować całą witrynę, natomiast systemy Google nie mają dostępu do sekcji „/private/”.
Najważniejsze, aby plik był zapisany w formacie UTF-8 i znajdował się w katalogu głównym domeny – np. https://twojadomena.pl/llms.txt.
Dzięki takiemu rozwiązaniu właściciel strony może w prosty sposób zarządzać tym, które treści trafiają do modeli językowych, bez potrzeby stosowania zaawansowanych zabezpieczeń czy konfiguracji serwera.
Jakie komendy obsługuje llms.txt?
Komenda „User-agent”
Ta dyrektywa określa, do którego programu odnosi się dana reguła.
Na przykład:
User-agent: GPTBot
Allow: /
oznacza, że wszystkie treści mogą być analizowane przez ChatGPT, natomiast inne systemy, których nie wymieniono, mogą mieć dostęp zablokowany.
Komendy „Allow” i „Disallow”
Za pomocą tych dwóch poleceń można bardzo precyzyjnie ustalić, które części witryny są dostępne dla sztucznej inteligencji.
- Allow: / – pozwala na analizę całej witryny,
- Disallow: /admin/ – blokuje dostęp do katalogu administracyjnego.
To proste, ale skuteczne rozwiązanie, które pozwala zachować równowagę pomiędzy otwartością a ochroną danych.
Nowe polecenia: „Allow-training” i „Allow-inference”
W najnowszych wersjach standardu pojawiają się rozszerzone dyrektywy.
- Allow-training – zezwala modelowi na wykorzystanie treści do procesu uczenia.
- Allow-inference – pozwala jedynie na analizę (bez zapisywania danych w pamięci modelu).
To ogromny krok w stronę etycznego wykorzystywania treści online i transparentności w świecie AI.
Czy plik llms.txt wpływa na pozycjonowanie stron?
Obecnie llms.txt nie ma bezpośredniego wpływu na klasyczne wyniki wyszukiwania w Google. Wyszukiwarki nie wykorzystują go do indeksowania stron – to zadanie wciąż spełnia robots.txt.
Jednak w dobie AI Overviews (czyli wyników generowanych przez sztuczną inteligencję) obecność llms.txt może pośrednio zwiększać widoczność witryny.
Strony, które zezwalają modelom AI na analizę swoich treści, są częściej cytowane w wynikach generatywnych, co zwiększa ich rozpoznawalność i zasięg.
Dlatego eksperci SEO rekomendują traktowanie llms.txt nie tylko jako zabezpieczenia, ale również jako elementu nowoczesnej optymalizacji w erze wyszukiwania opartego na sztucznej inteligencji.
Jak llms.txt wpływa na SEO i widoczność w AI Overviews?
Plik llms.txt staje się jednym z narzędzi nowej generacji SEO, określanej mianem Generatywnej optymalizacji wyszukiwarek.
Nie wpływa bezpośrednio na ranking, ale buduje zaufanie i zwiększa szanse na to, że Twoja witryna zostanie uwzględniona w odpowiedziach generatywnych.
W praktyce strony, które wdrożyły ten plik, są lepiej interpretowane przez modele językowe – ich dane są uporządkowane, a struktura transparentna. To czynnik, który w nadchodzących latach może mieć coraz większe znaczenie.
Czy warto wdrożyć llms.txt w 2025 roku?
Zdecydowanie tak. Wdrożenie llms.txt jest szybkie, proste i darmowe, a korzyści – długoterminowe.
Pozwala nie tylko chronić treści, ale także przygotować stronę na przyszłość, w której sztuczna inteligencja stanie się podstawowym narzędziem wyszukiwania i analizy danych.
Podobnie jak kilka lat temu certyfikat SSL stał się obowiązkowy standardem, tak dziś llms.txt staje się elementem odpowiedzialnego i świadomego zarządzania treściami online.
Jak sprawdzić, czy Twój plik llms.txt działa poprawnie?
Najprostszym sposobem jest wpisanie w przeglądarce adresu https://twojadomena.pl/llms.txt.
Jeśli plik otwiera się bez błędów – działa prawidłowo.
Dodatkowo można użyć narzędzi takich jak Screaming Frog czy Sitebulb
Tabela porównawcza plików llms.txt, robots.txt i sitemap.xml
Aktualizacja: OpenAI potwierdza aktywność wobec pliku llms.txt (lipiec 2025)
W drugiej połowie lipca 2025 roku branża SEO zyskała pierwsze techniczne potwierdzenie, że boty OpenAI rzeczywiście odczytują pliki llms.txt umieszczone na stronach internetowych.
Według informacji udostępnionych przez Search Engine Roundtable, specjalista SEO Ray Martinez przeanalizował logi serwera, w których pojawiły się regularne zapytania od agenta OAI-SearchBot/1.0.
Bot ten, przypisany do infrastruktury OpenAI, pobierał plik llms.txt z adresu https://www.archersite.com/llms.txt średnio co kilkanaście minut, sprawdzając jego aktualność. Analiza ruchu potwierdziła, że połączenia pochodziły z autentycznych adresów IP należących do OpenAI, a więc nie były wynikiem testów zewnętrznych czy symulacji.
Jak podkreślił Martinez, jego logi jednoznacznie wskazują, że OpenAI aktywnie monitoruje zawartość plików llms.txt na wybranych witrynach, co może sugerować początek rzeczywistego wdrażania tego standardu w praktyce.
„Analiza logów pokazuje, że bot OpenAI regularnie sprawdza mój plik LLMS.txt, szukając najnowszej wersji co kilkanaście minut.” — Ray Martinez, lipiec 2025
Choć dla wielu ekspertów SEO to znaczący krok naprzód i dowód, że idea llms.txt zaczyna nabierać realnych kształtów, jest jeszcze zbyt wcześnie, by wyciągać ostateczne wnioski.
Brak oficjalnego stanowiska OpenAI w tej sprawie oraz ograniczona liczba udokumentowanych przypadków oznaczają, że temat należy traktować jako obiecujący, ale wciąż eksperymentalny.
Warto obserwować rozwój sytuacji, testować wdrożenia i analizować dane, jednak na razie nie ma powodu, by podejmować pochopne decyzje dotyczące strategii SEO lub AI compliance.
Dobre praktyki dla tworzenia poprawnego pliku llms.txt
Tworzenie skutecznego pliku llms.txt wymaga połączenia technicznej precyzji z jasnym zrozumieniem, jak modele sztucznej inteligencji odczytują i interpretują dane. Prawidłowo skonstruowany plik nie tylko zabezpiecza treści, ale też zwiększa przejrzystość Twojej witryny dla systemów AI. Poniżej przedstawiono najważniejsze zasady, które pomogą Ci przygotować llms.txt zgodnie z najlepszymi praktykami roku 2025.
Optymalizacja treści pod kątem zrozumienia przez sztuczną inteligencję
Modele językowe analizują dane inaczej niż tradycyjne roboty wyszukiwarek — skupiają się na znaczeniu, kontekście i logicznych relacjach pomiędzy fragmentami tekstu.
Dlatego treści, do których uzyskują dostęp poprzez llms.txt, powinny być napisane w sposób:
- klarowny i jednoznaczny, bez zbędnych skrótów myślowych,
- semantycznie spójny, czyli z dobrze zdefiniowanymi nagłówkami i logicznym porządkiem,
- naturalny językowo, unikający sztucznego nasycenia słów kluczowych.
Treść napisana w ten sposób jest nie tylko lepiej rozumiana przez modele AI, ale też częściej cytowana w generatywnych wynikach wyszukiwania (AI Overviews).
Zasada fragmentacji (chunkowania): pisanie z myślą o łatwym wyodrębnianiu informacji
Chunkowanie to technika, która polega na dzieleniu treści na małe, logiczne fragmenty – tzw. chunki.
Każdy chunk powinien skupiać się na jednym temacie i zawierać wystarczająco informacji, by model mógł go zrozumieć bez dodatkowego kontekstu.
Dobre praktyki chunkowania:
- Twórz akapity, które nie przekraczają 4–5 zdań.
- Każdy akapit powinien zawierać jedną główną ideę.
- Używaj nagłówków H2 i H3, by jasno oddzielać tematy.
- Wprowadzaj naturalne słowa przejściowe, takie jak dlatego, w rezultacie, z kolei, ponadto.
Dzięki temu modele językowe mogą szybciej i trafniej interpretować znaczenie treści, co zwiększa ich szansę na wykorzystanie w odpowiedziach generatywnych.
Klarowność i struktura: podstawy treści przyjaznych dla LLM
Modele LLM (Large Language Models) cenią porządek i przejrzystość.
Każdy element treści powinien mieć jasno określoną rolę — od nagłówków, przez akapity, po przykłady i dane.
Zadbaj o to, aby:
- używać zrozumiałych nagłówków, które precyzyjnie opisują temat sekcji,
- unikać długich, wielokrotnie złożonych zdań,
- budować strukturę opartą na zasadzie „od ogółu do szczegółu”,
- stosować ujednolicony format w całym dokumencie (np. ten sam sposób zapisu poleceń i nazw botów).
Dobrze ustrukturyzowany tekst jest łatwiejszy w analizie — zarówno dla ludzi, jak i dla systemów sztucznej inteligencji.
Przemyślana selekcja: co uwzględnić, a co pominąć
Plik llms.txt daje właścicielom stron możliwość decydowania, które sekcje ich witryny mogą być analizowane przez modele AI.
Warto podejść do tego strategicznie:
Udostępniaj treści publiczne, blogi, poradniki, opisy produktów czy FAQ – zwiększają widoczność w generatywnych wynikach.
Wykluczaj strony prywatne, panele administracyjne, dane użytkowników i zasoby płatne.
Regularnie analizuj logi serwera, aby sprawdzać, które boty odczytują plik llms.txt (np. OAI-SearchBot, Google-Extended).
Aktualizuj zasady przynajmniej raz w miesiącu — wiele botów odświeża plik automatycznie co kilka godzin.
Zbyt restrykcyjne reguły mogą ograniczyć zasięg w środowisku generatywnego wyszukiwania, natomiast zbyt liberalne — narazić dane na nieautoryzowany dostęp.
Najczęściej zadawane pytania o plik llms.txt
Co to jest plik llms.txt?
Plik llms.txt to prosty dokument tekstowy umieszczany w katalogu głównym strony internetowej, który informuje modele sztucznej inteligencji (np. ChatGPT, Gemini, Claude, Perplexity AI), jakie treści mogą być analizowane, a które powinny pozostać niedostępne. Działa podobnie jak robots.txt, ale jest przeznaczony wyłącznie dla systemów AI, a nie wyszukiwarek.
Czy plik llms.txt działa?
Tak, ale jego skuteczność zależy od tego, czy dany model AI respektuje jego zasady. Obecnie stosują go największe systemy, takie jak GPTBot, Google-Extended, ClaudeBot czy Perplexity AI. Warto jednak pamiętać, że nie wszystkie modele przestrzegają jeszcze tego standardu, dlatego jego efektywność może się różnić w zależności od źródła ruchu.
Jakie są wersje pliku llms.txt?
Obecnie funkcjonuje wersja 1.0 pliku llms.txt, opracowana w 2024 roku przez społeczność AI Compliance oraz organizacje takie jak OpenAI i Anthropic. Trwają prace nad wersją 1.1, która ma wprowadzić dodatkowe dyrektywy, np. Allow-training i Allow-inference, pozwalające rozróżnić dostęp do treści w celach uczenia lub analizy.
Jakie są opinie na temat pliku llms.txt?
Opinie w branży są podzielone. Część ekspertów uważa plik llms.txt za niezbędny element przyszłości SEO i ochrony danych, inni podkreślają, że jego skuteczność nie została jeszcze w pełni potwierdzona. Warto obserwować jego rozwój i testować rozwiązanie, zwłaszcza że może ono wkrótce stać się standardem w komunikacji między stronami a modelami AI.
Czy plik llms.txt wpływa na pozycjonowanie w Google?
Bezpośrednio nie. Googlebot nie korzysta z pliku llms.txt, jednak dane dostępne dla modeli AI mogą wpływać na widoczność witryny w generatywnych wynikach wyszukiwania, tzw. AI Overviews. Dlatego eksperci zalecają, by traktować ten plik jako część strategii SEO w erze sztucznej inteligencji.
Jak dodać plik llms.txt do swojej strony?
Aby wdrożyć plik llms.txt, wystarczy utworzyć plik tekstowy w formacie UTF-8, dodać odpowiednie komendy User-agent, Allow i Disallow, a następnie umieścić go w katalogu głównym domeny. Przykład adresu: https://twojadomena.pl/llms.txt.
Jak sprawdzić, czy plik llms.txt działa poprawnie?
Plik można przetestować, wpisując jego adres w przeglądarce lub używając komendy curl. Dodatkowo narzędzia SEO, takie jak Screaming Frog czy Sitebulb, wprowadzają już obsługę tego standardu, co ułatwia jego weryfikację.
Czy warto wdrożyć plik llms.txt w 2025 roku?
Tak. Choć standard jest jeszcze nowy, wdrożenie llms.txt może pomóc w budowaniu transparentności i przygotować stronę na zmieniające się zasady interakcji z modelami AI. Dla wielu firm to krok w stronę nowoczesnego, etycznego zarządzania treścią.
Co przyniesie przyszłość pliku llms.txt?
W kolejnych latach można spodziewać się rozwoju standardu i jego szerszego przyjęcia przez duże organizacje technologiczne. Możliwe, że w przyszłości stanie się on integralnym elementem SEO oraz obowiązkowym elementem polityki transparentności danych w sieci.
Co się stanie, jeśli nie mam pliku llms.txt?
Brak tego pliku nie powoduje kar, ale oznacza, że modele AI mogą analizować Twoje treści bez kontroli. Jeśli chcesz chronić dane i zarządzać dostępem, warto taki plik wdrożyć.
Czy llms.txt można połączyć z robots.txt?
Tak, oba pliki mogą współistnieć, ale każdy ma inną funkcję – robots.txt kontroluje wyszukiwarki, a llms.txt modele sztucznej inteligencji.
Jakie systemy AI respektują llms.txt?
Obecnie są to m.in. GPTBot (OpenAI), Google-Extended, ClaudeBot (Anthropic) i Perplexity AI. Lista ta szybko się rozszerza, dlatego wdrożenie pliku już dziś to krok w stronę przyszłości.
Podsumowanie
Plik llms.txt wciąż wzbudza wiele emocji – ma zarówno swoich zwolenników, jak i sceptyków. Choć jego skuteczność nie została jeszcze jednoznacznie potwierdzona, z pewnością warto obserwować jego rozwój i testować go w praktyce. Zmiany w świecie SEO i sztucznej inteligencji zachodzą tak szybko, że elastyczność i otwartość na nowe rozwiązania stają się dziś kluczowe.